 Bulk email list cleaning at scale is the process of validating every address in a large contact database, typically 500,000 to tens of millions of records, for deliverability before it's used for sending, without the per-record cost or processing time becoming a bottleneck.
Bulk email list cleaning at scale is the process of validating every address in a large contact database, typically 500,000 to tens of millions of records, for deliverability before it's used for sending, without the per-record cost or processing time becoming a bottleneck.
Most email verification tools are built and priced for lists in the tens of thousands. At 1M+ contacts, three things change simultaneously: cost, throughput, and error tolerance. A pricing model that looks reasonable at 10,000 emails can become a five- or six-figure line item at 1M. A verification API that returns results in seconds for a small batch can time out or throttle when you're pushing millions of rows through it. And a single systemic error like misclassifying a major provider's catch-all domains, gets multiplied across hundreds of thousands of records instead of dozens.
This is why bulk cleaning at scale needs to be treated as a distinct engineering problem, not just "the same thing, but bigger."
What Bulk Email List Cleaning at Scale Actually Means
 Bulk email list cleaning at scale combines several operations run across an entire contact database, syntax validation, domain/MX validation, mailbox-level deliverability checks, risk classification (catch-all, disposable, role-based, spam trap patterns), and deduplication, all executed within a cost and time budget that scales linearly, not exponentially, with list size.
Bulk email list cleaning at scale combines several operations run across an entire contact database, syntax validation, domain/MX validation, mailbox-level deliverability checks, risk classification (catch-all, disposable, role-based, spam trap patterns), and deduplication, all executed within a cost and time budget that scales linearly, not exponentially, with list size.
Each of the core checks maps to a distinct technical step:
- Syntax validation confirms the address conforms to RFC 5322 formatting rules before any network call is made. This is the cheapest check and should always run first to filter out obviously malformed rows.
- Domain and MX validation confirms the domain resolves and has valid mail exchange (MX) records, per DNS standards. An address on a domain with no MX record is undeliverable regardless of mailbox status.
- Mailbox-level SMTP verification opens an SMTP session with the recipient's mail server and checks whether the specific mailbox exists, following the connection sequence defined in RFC 5321, without actually delivering a message.
- Risk classification flags catch-all domains (which accept mail to any address at that domain and therefore can't be verified at the mailbox level), disposable/temporary email services, role-based addresses (info@, support@, sales@), and known spam trap patterns.
At list sizes under 50,000, all four checks can run against a single verification request without much thought to infrastructure. At 1M+, the SMTP verification step becomes the constraint, because receiving mail servers throttle, greylist, or temporarily reject high-volume verification traffic exactly the way they throttle spam.
The Real Cost of Skipping Email Verification at Scale
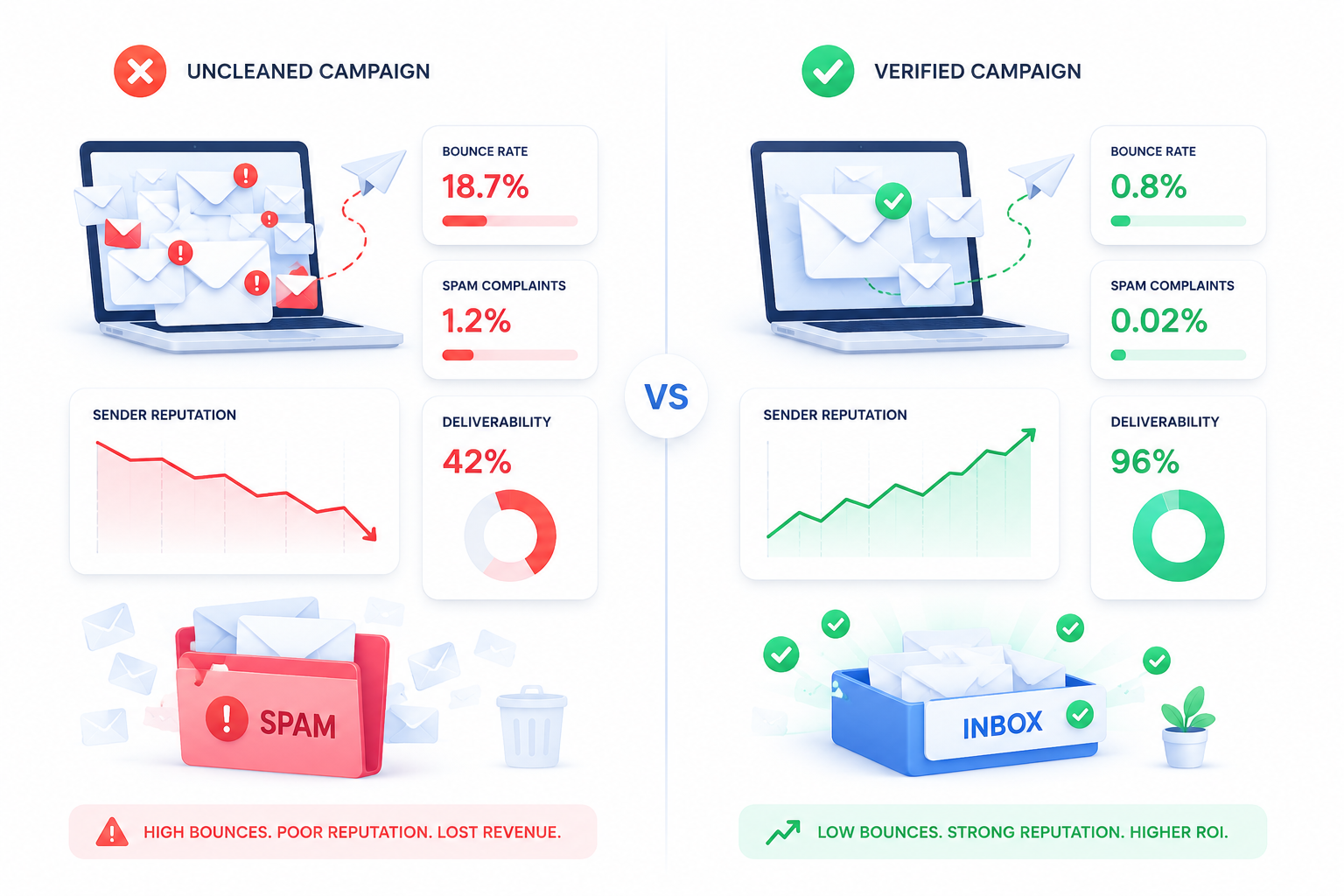
Sending to an uncleaned list of 1M+ contacts doesn't fail cleanly, it degrades sender reputation gradually, and the damage compounds.
Gmail's bulk sender guidelines require senders of 5,000+ daily messages to keep spam complaint rates below 0.3% and bounce rates under recommended thresholds, and enforcement applies regardless of which email service provider you send through. A list that hasn't been cleaned in six or more months commonly carries a meaningful share of invalid or risky addresses, the exact rate depends on acquisition source (organic signups decay slower than purchased or scraped lists), which is often enough to push bounce rates past provider thresholds on the very first send.
The compounding cost breaks down into three categories:
| Cost category | What happens | Why it's expensive at 1M+ scale |
|---|---|---|
| Sender reputation damage | High bounce/complaint rates get flagged by mailbox providers, throttling or blackholing future sends | Reputation is domain-wide, one bad send from a dirty segment can suppress deliverability for your entire program |
| Wasted sending infrastructure spend | You pay your ESP to send to addresses that will never deliver | For example, on a 1M-contact list where 15% are invalid, that's 150,000 wasted sends every campaign |
| Spam trap hits | Pristine and recycled spam traps look like real addresses but exist only to catch bad senders | A handful of trap hits on a 1M-record list can trigger blocklisting that takes weeks to resolve |
This is the core argument for verifying before every major send, not just once at list import: list decay is continuous, and at 1M+ contacts the blast radius of a bad send is proportionally larger.
How Email Verification Works Under the Hood
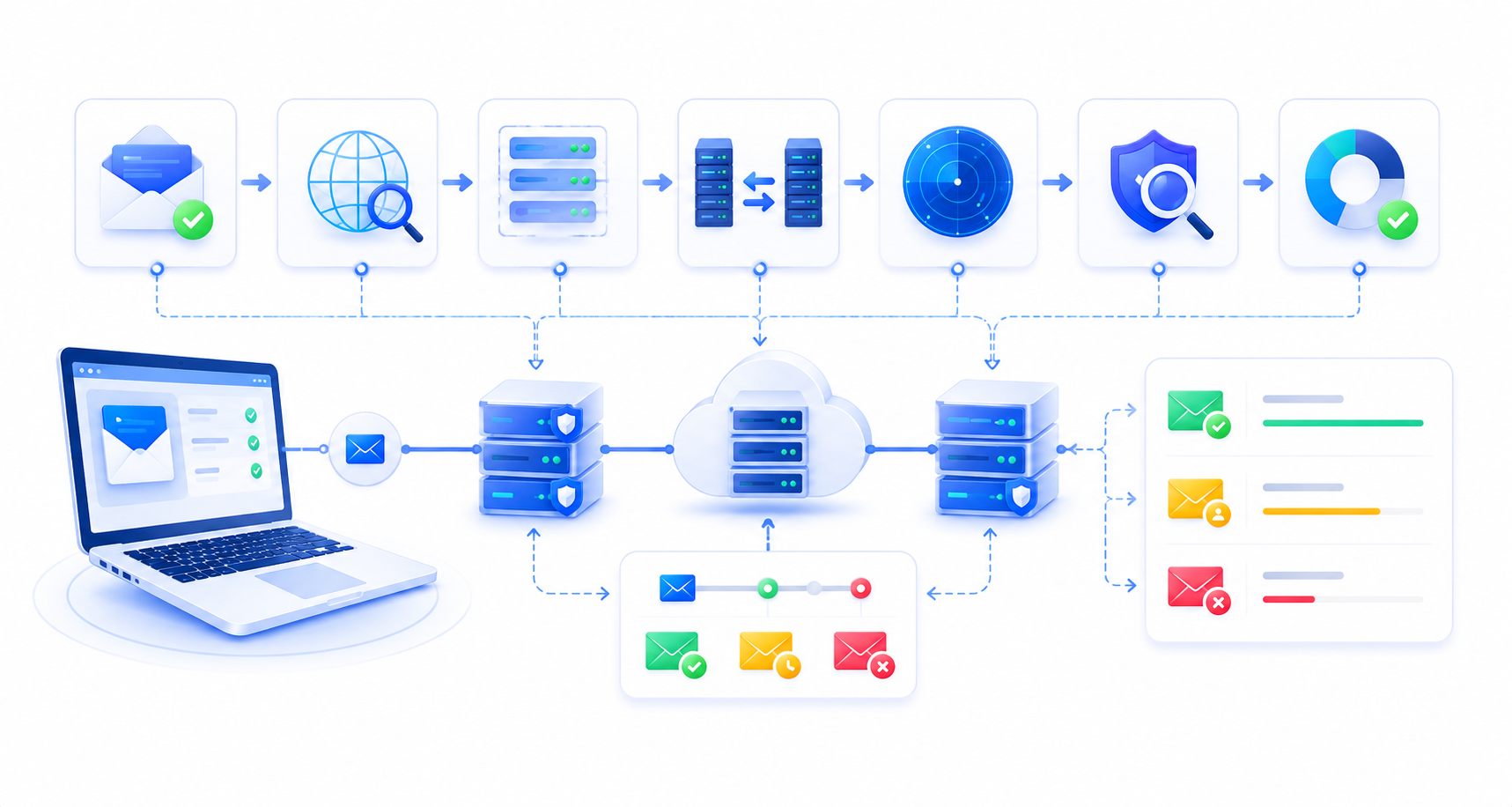
A production-grade bulk verification pipeline runs each address through a layered pipeline, rejecting cheaply where possible and only paying the cost of a full SMTP handshake when necessary.
1. Syntax and format check. Regex-based validation against RFC 5322. Near-zero cost, executed locally, and typically filters out a small share of a raw list: malformed entries, typos, and obviously broken addresses, instantly.
2. DNS and MX resolution. A DNS lookup confirms the domain exists and has valid MX records. Results are cacheable, verifying 1M contacts against a database with a few thousand unique domains means most MX lookups hit a cache after the first pass.
3. SMTP handshake / mailbox verification. The verifier's mail server opens a connection to the recipient's MX server and issues the SMTP RCPT TO command, reading the response code without sending a message — a technique sometimes called callback verification. Response codes fall into three buckets: 2xx (mailbox exists), 5xx (permanent failure, invalid mailbox), and 4xx (temporary failure, often from greylisting as described in RFC 6647, where a server defers and expects a retry).
4. Catch-all and risk classification. If a domain accepts mail to any address, the SMTP check alone can't confirm a specific mailbox exists. Verification tools flag these as "catch-all" or "risky" rather than false-labeling them valid or invalid, and apply secondary heuristics (pattern matching, historical engagement data where available) to refine the classification.
5. Deduplication and normalization. Addresses are normalized (lowercasing domains, handling provider-specific aliasing like Gmail's dot-insensitivity) and deduplicated before final scoring, since duplicate records otherwise get billed and processed twice.
The step that breaks naive implementations at scale is greylisting retries. A receiving server that returns a 4xx response is asking the sender to try again later, legitimate mail servers do this and succeed on retry. A verification pipeline that doesn't respect this and instead marks every 4xx as "unknown" or "invalid" will misclassify a meaningful percentage of otherwise-valid addresses on large lists, especially those hosted on providers with aggressive greylisting policies.
Architecture Patterns for Cleaning 1M+ Contacts
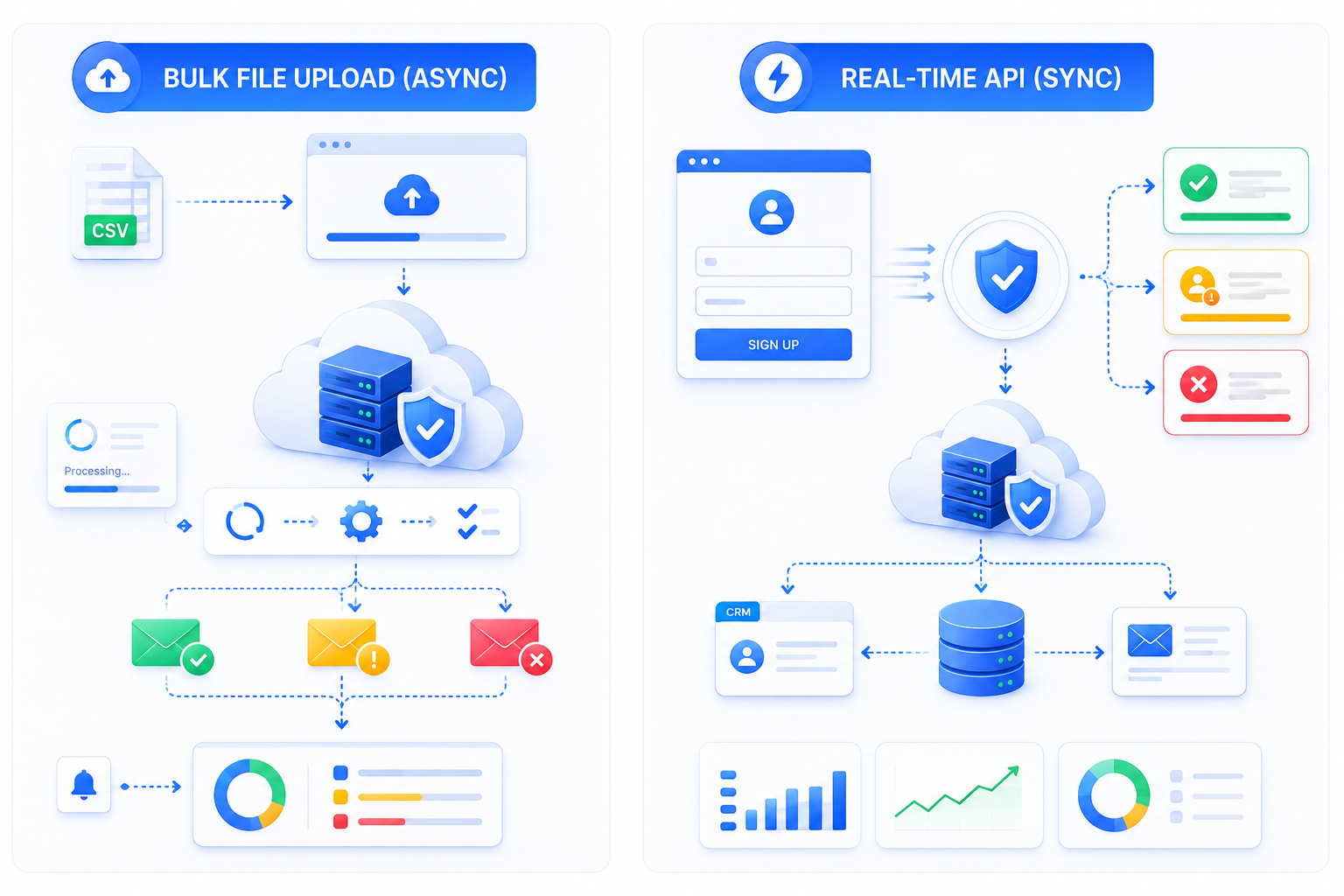
At 1M+ records, the practical choice is between two integration patterns, and the right one depends on how the cleaning fits into your existing pipeline.
Pattern 1: Bulk file upload with async processing
Upload a CSV or connect a data source, let the verification provider process the full file asynchronously, and retrieve results via a completion webhook or polling endpoint. This is the simpler pattern operationally, no need to manage your own queue or worker pool but you're dependent on the provider's processing throughput and job status visibility.
Best for: one-off cleans, quarterly hygiene sweeps, migrating a list before a new campaign.
Pattern 2: Real-time Email Verification API integrated into your ingestion pipeline
Call the verification API per-record (or in small batches) at the point of capture: signup forms, CRM imports, CSV uploads into your own system, so invalid addresses never make it into your database in the first place.
Best for: continuous list hygiene where new contacts flow in daily and you want to catch bad addresses before they accumulate into a future bulk-clean cost.
Most teams maintaining 1M+ contact databases run both: real-time API verification at the point of capture to prevent decay, plus a scheduled bulk re-verification pass (monthly or quarterly) to catch mailboxes that have gone stale since the original signup, a role-based inbox that's since been decommissioned, or a personal address abandoned after a job change.
A minimal batch-processing setup for the bulk pattern looks like this:
1. Split source file into chunks (e.g., 50K records per chunk)
2. Submit each chunk to the bulk verification endpoint
3. Poll job status or listen for webhook completion per chunk
4. Merge results back into source records by unique ID
5. Route by status: valid → keep, invalid → suppress, risky/catch-all → tag for
manual review or lower-priority send segment
Chunking matters less for API rate limits (most bulk endpoints are designed for large single uploads) and more for operational resilience, if a chunk fails or times out, you re-run 50K records, not 1M.
The Bulk Email Verification Pricing Models You'll Encounter and the Math Behind Them
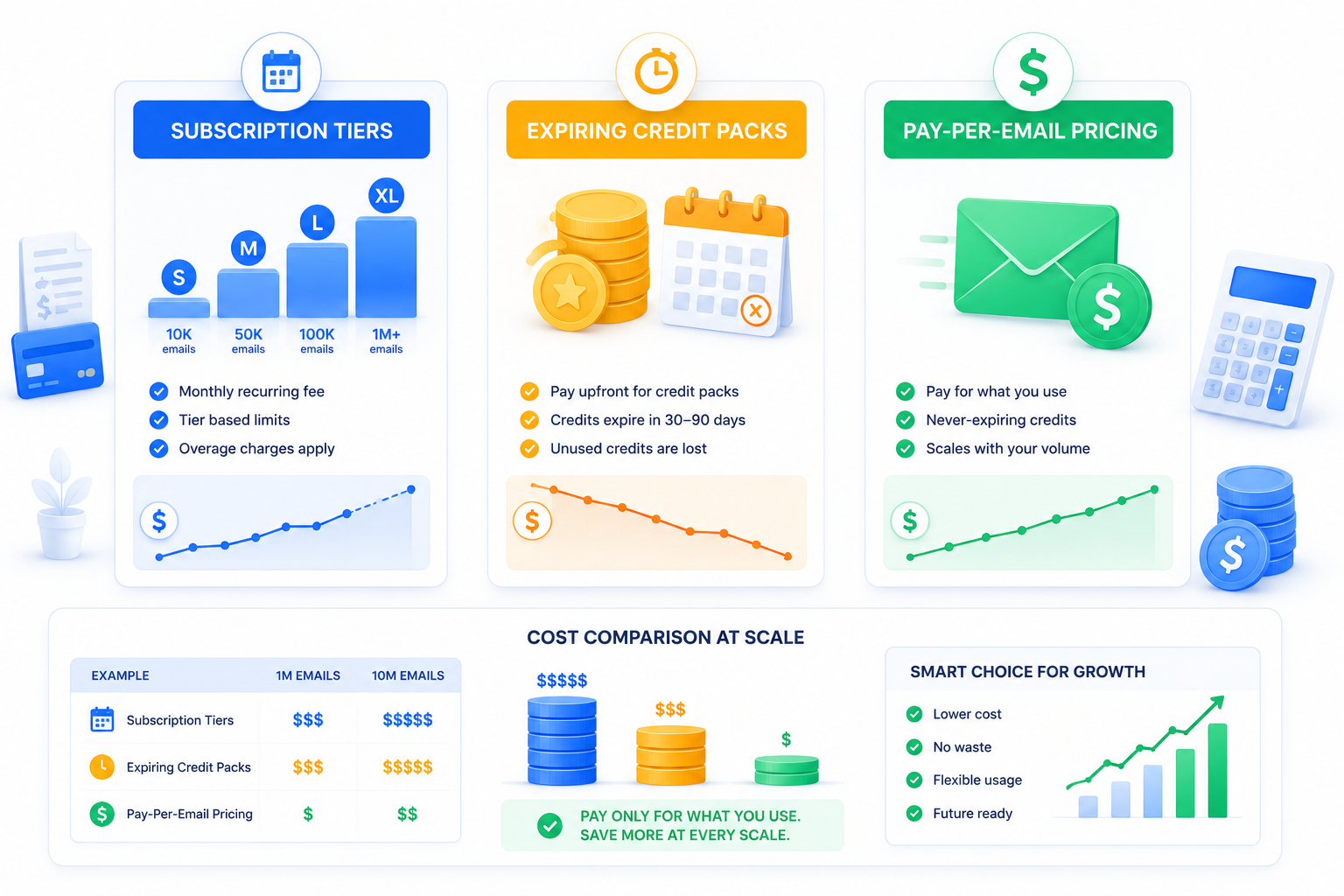
Bulk email verification pricing generally falls into three models, and at 1M+ contacts the difference between them can mean tens of thousands of dollars per year.
| Pricing model | How it works | Where it breaks down at scale |
|---|---|---|
| Tiered monthly subscription | Fixed monthly fee for a volume tier (e.g., up to 100K verifications/month) | Overage fees or forced upgrades once you cross the tier boundary, even by a few thousand records |
| Per-verification credit packs with expiration | You buy a block of credits (e.g., 1M credits) that expire in 30-90 days | Credits you don't use within the window are forfeited, costly if your cleaning cadence is quarterly, not monthly |
| Flat per-email pricing with never-expiring credits | You pay a fixed rate per email verified (for example, $0.001/email), and unused credits roll over indefinitely | Rare among vendors, but the only model that scales cleanly for infrequent large cleans |
The math matters more than it looks at first glance. At $0.001 per email:
- Cleaning 1,000,000 contacts costs $1,000.
- Cleaning 10,000,000 contacts costs $10,000.
- Re-verifying the same 1M-contact list quarterly costs $4,000/year, not $12,000, because there's no forced monthly minimum.
Compare that to a tiered subscription priced for "up to 1M/month" that costs $1,200/month regardless of whether you clean the list once a quarter or four times, you'd pay $14,400/year for the same volume of actual verification work.
Why Per-Email Pricing and Never-Expiring Credits Matter at Scale
For teams that clean large lists periodically rather than continuously, flat per-email pricing with credits that don't expire removes the two biggest cost inefficiencies in bulk verification: forced monthly minimums and forfeited unused capacity.
This matters specifically for growth and DevOps teams because list-cleaning cadence is rarely a smooth monthly curve. A common real pattern looks like: verify the full 2M-contact database once before a major re-engagement campaign, then only verify new signups in real time for the next five months, then do another full sweep before the next big send. A subscription model penalizes this pattern by billing for capacity you're not using in the quiet months. A never-expiring, per-email credit model charges you only for what you actually verify, whenever you verify it — which is why the cost comparison is most stark exactly at the 1M+ scale this playbook is about: the absolute dollar gap between models widens with volume, even though the percentage difference stays constant.
If you're deciding between vendors for a 1M+ cleanup, run the math against your actual cleaning cadence (not the vendor's assumed monthly cadence) before comparing sticker prices.
Step-by-Step: Cleaning a 1M+ Email Contact List
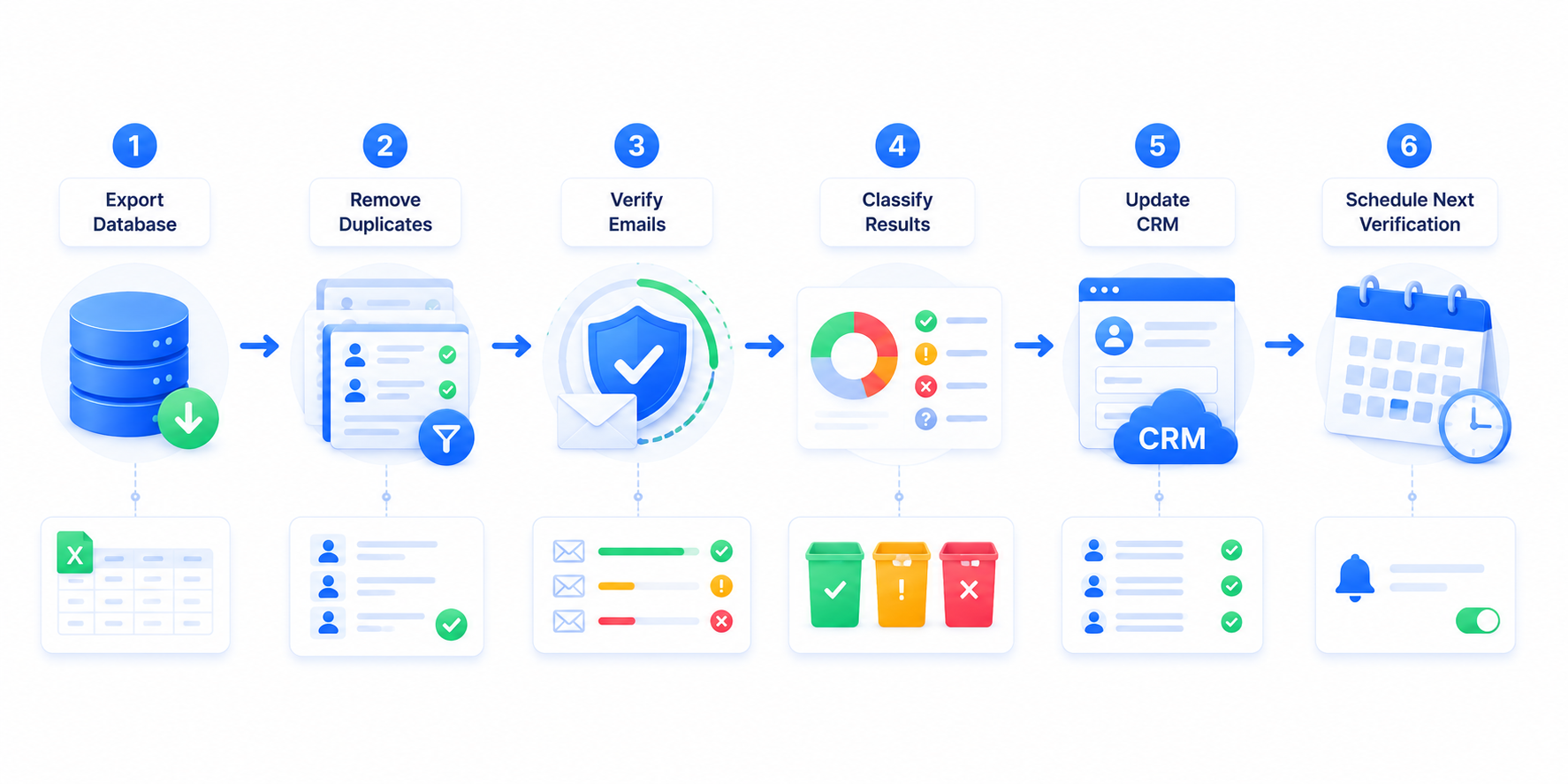
- Export and snapshot the source list. Keep a timestamped copy before any modification so suppressions are reversible if something goes wrong.
- Deduplicate and normalize first. Remove exact duplicates and normalize casing/formatting before sending anything to a verification API — this alone often reduces a "1M contact" list to a smaller set of unique billable records, cutting cost before verification even starts.
- Run bulk verification in chunks. Submit in batches of 50K-100K records for operational resilience, using async processing rather than blocking on a single massive request.
- Wait for full classification, not partial results. Catch-all and greylisted addresses sometimes need a second-pass retry; don't suppress based on a first response that hasn't resolved.
- Segment by status. At minimum: valid (safe to send), invalid (suppress permanently), catch-all/risky (send in a lower-priority or monitored segment), disposable (suppress), role-based (suppress or deprioritize based on your use case).
- Update your source of truth. Write verification status and timestamp back to your CRM or ESP so future sends reference current data, not the raw import.
- Schedule the next pass. Set a recurring reminder or automated job for 60-90 days out, list decay from job changes, abandoned inboxes, and provider policy changes is continuous.
Common Mistakes That Inflate Cost or Wreck Accuracy
- Verifying before deduplicating. Paying to verify the same address twice because it appears under two record IDs is a pure waste of budget at scale — dedupe first.
- Treating catch-all as invalid. Catch-all domains are common at business domains (many companies configure their mail servers to accept any address at their domain). Suppressing them outright can strip a meaningful share of an otherwise-valid B2B list.
- Ignoring greylisting retries. As noted above, a 4xx response deserves a retry, not an immediate "unknown" classification — misreading this inflates your unknown/risky bucket and understates true list quality.
- Choosing a vendor based on accuracy claims alone. Accuracy percentages are marketing numbers; ask specifically how catch-all, disposable, and role-based addresses are classified, since that's where vendors differ most in practice.
- Ignoring credit expiration windows when budgeting. A "cheap" credit pack that expires in 30 days is not cheap if your actual cleaning cadence is quarterly.
Build vs. Buy: A Decision Framework
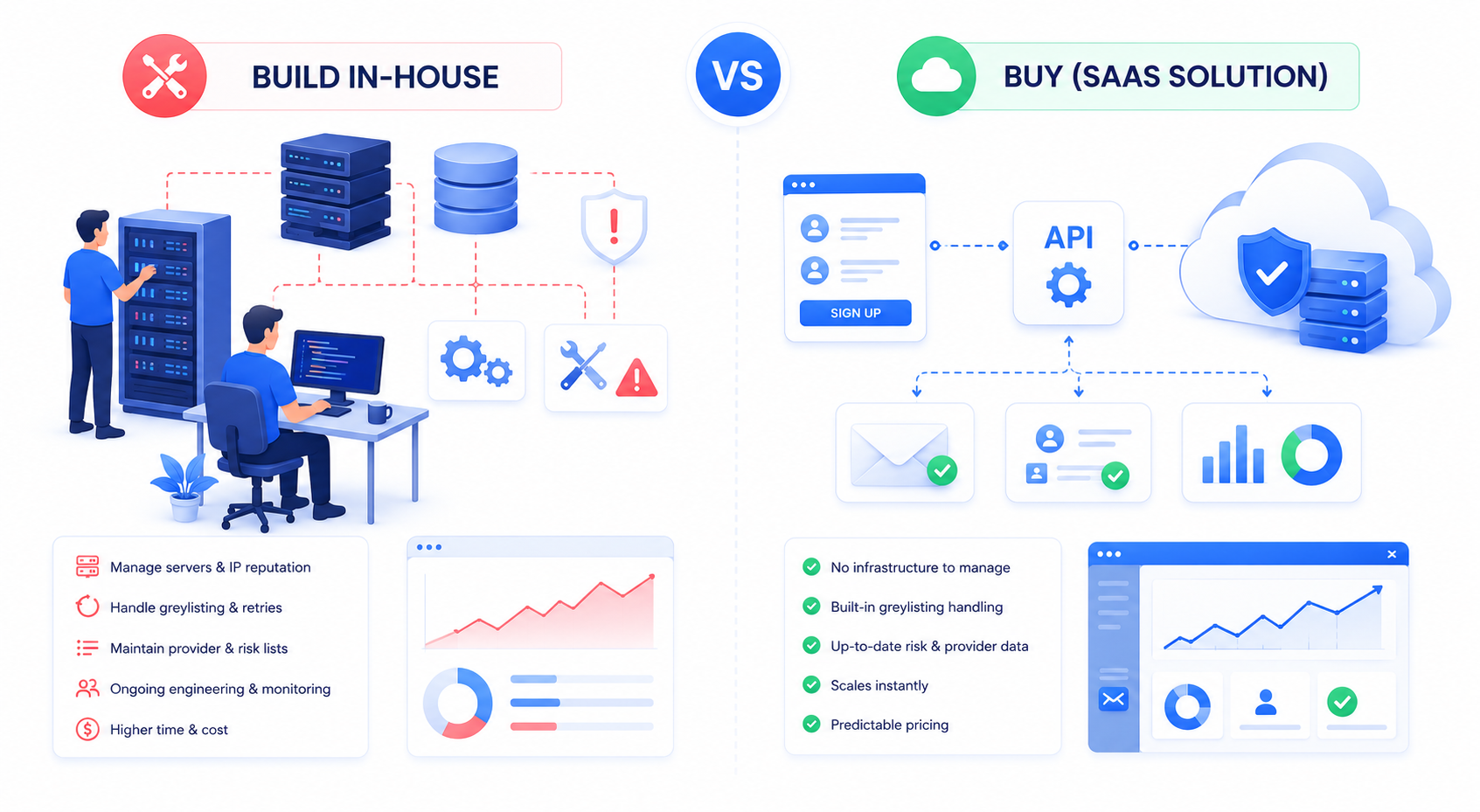
Building an in-house SMTP verification pipeline is technically straightforward for a proof of concept and genuinely hard to operate reliably at 1M+ scale.
Consider building in-house if: - Verification volume is a small, steady trickle (a few thousand per day) tied to real-time signup flows only. - You have existing infrastructure for managing IP reputation, since your own verification servers will need to avoid being blocklisted by receiving mail servers. - Compliance or data residency requirements prevent sending contact data to a third party.
Consider buying (API/bulk service) if: - You're cleaning 100K+ records in a single pass, where IP reputation management and greylisting-aware retry logic become a full engineering project on their own. - You need catch-all and disposable classification that's kept current against an evolving list of providers, this is a maintenance burden, not a one-time build. - Cost predictability matters, and you'd rather pay a known per-email rate than staff and maintain verification infrastructure.
MailValid handles this trade-off directly for growth and DevOps teams: bulk verification runs through a single API or file upload, pricing is a flat $0.001 per email with credits that never expire, and the underlying pipeline already handles catch-all detection, disposable/role-based flagging, and greylisting-aware retries, so the engineering effort is integration, not infrastructure maintenance.
Frequently Asked Questions
How much does it cost to verify 1 million email addresses? At a flat rate of $0.001 per email, verifying 1 million addresses costs approximately $1,000. Total cost varies by vendor and pricing model — tiered subscriptions and expiring credit packs can cost significantly more for the same volume if your cleaning cadence doesn't match the plan's billing cycle.
How long does it take to verify a list of 1M+ contacts? Bulk verification of 1M+ contacts typically completes within a few hours using async batch processing, though exact timing depends on how many addresses require greylisting retries and how the provider parallelizes SMTP checks across mail servers.
What's the difference between bulk verification and real-time API verification? Bulk verification processes an entire file or list at once, usually via async job with webhook or polling-based results, and is best for periodic list cleaning. Real-time API verification checks a single address on demand — typically at the point of signup or import — and is best for stopping bad addresses from entering your database in the first place.
Do unused verification credits expire? It depends on the vendor. Many providers sell credit packs that expire in 30-90 days, which can waste budget for teams that clean lists quarterly rather than monthly. Providers offering never-expiring credits let you buy capacity once and use it whenever your actual cleaning cadence requires it.
What is a catch-all domain, and why can't it always be verified? A catch-all domain is configured to accept mail sent to any address at that domain, including addresses that don't correspond to a real mailbox. Because the receiving mail server won't reject an SMTP verification attempt for these domains, verifiers can't confirm a specific mailbox exists and instead flag the address as "catch-all" or "risky" rather than definitively valid or invalid.
Will cleaning my list improve my sender reputation immediately? Cleaning removes invalid and high-risk addresses before your next send, which reduces bounce and complaint rates on that send. Sender reputation with mailbox providers like Gmail is typically assessed on a rolling basis, so reputation recovery after a history of high bounce rates takes multiple clean sends over time, not a single cleaning pass.
MailValid Team
Email verification experts
Join developers who verify smarter
Stop letting bad emails hurt your deliverability
100 free credits. $0.001/email after. Credits never expire. No credit card required.